A definitive breakdown of the 2025 Microsoft Outlook outage. Learn what caused the crash, its worldwide impact, and how to protect your business from the next one.
A deep dive into the technical catastrophe that brought businesses to a standstill, the massive global impact, and the crucial lessons we all must learn.
Where were you on the morning of April 15, 2025? It’s a question that now joins the ranks of historic “do you remember?” moments. For millions, the answer is the same: staring at a frozen screen, hitting refresh on a useless inbox, and slowly realizing that their primary mode of communication was gone. The Microsoft Outlook Outage 2025 wasn’t just another tech glitch; it was a digital blackout that sent a shockwave through the global economy, reminding us just how fragile our interconnected world truly is.
This outage wasn’t a simple server issue. It was a complex, multi-layered failure that impacted not just Outlook but the entire Microsoft 365 ecosystem. In this definitive analysis, we will dissect the timeline of the crash, explain the technical root causes in plain English, explore the profound financial and operational impacts, and outline the critical, actionable takeaways for businesses and individuals to ensure they are never caught this vulnerable again.

A Timeline of the Great Digital Silence
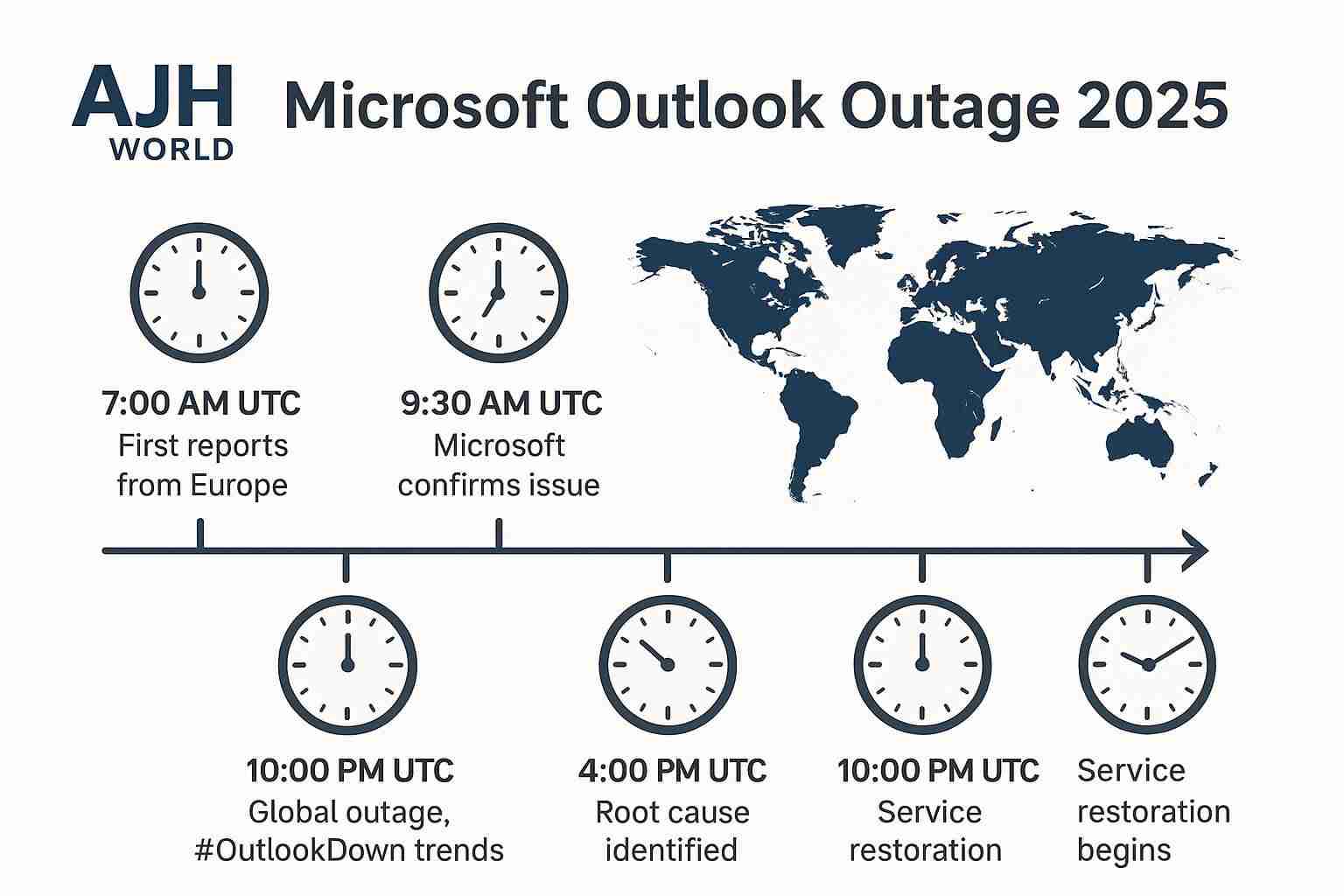
The outage didn’t happen all at once. It was a rolling catastrophe that spread across time zones, starting just as the European markets opened and hitting the U.S. East Coast at the peak of its morning rush.
- 7:00 AM UTC (3:00 AM ET): First reports surface from IT admins in Europe. Users are unable to sync inboxes or send new emails. The issue is initially dismissed as a localized network problem.
- 9:30 AM UTC (5:30 AM ET): Microsoft’s service health dashboard acknowledges “an emerging issue” affecting Exchange Online services. Panic begins to set in.
- 12:00 PM UTC (8:00 AM ET): The outage is global. #OutlookDown trends worldwide. Teams, OneDrive, and other Microsoft 365 services experience severe degradation as the underlying infrastructure fails.
- 4:00 PM UTC (12:00 PM ET): Microsoft isolates the root cause but warns that the fix will require a gradual and careful rollback, predicting hours more of disruption.
- 10:00 PM UTC (6:00 PM ET): Service begins to be restored for some users, but full functionality isn’t achieved for nearly 20 hours after the first reports.
What Caused the Microsoft Outlook Outage 2025? The Perfect Storm
This wasn’t a malicious attack, but a terrifying case of a “perfect storm”—two independent technical failures that converged into a single, catastrophic event.
The First Domino: A Flawed Routine Patch
It all started with a seemingly harmless routine software update pushed to a core part of Microsoft’s Azure infrastructure—the vast network that powers Outlook and Microsoft 365. This patch contained a subtle bug that, under specific load conditions, caused critical authentication servers to fail. These servers are the gatekeepers; without their approval, your Outlook client can’t prove who you are, and the system denies you access. Read more Trump’s Tariff Shockwaves: A Guide to the Potential Trump Tariff Market Impact 2025
The Knockout Punch: A Cascading BGP Failure
Ordinarily, Microsoft’s redundancy would have isolated the failing servers. However, at almost the same time, an unrelated error occurred: a BGP (Border Gateway Protocol) route leak.
Think of BGP as the internet’s GPS. It tells data how to get from point A (your computer) to point B (Microsoft’s servers). A major telecom partner inadvertently broadcasted incorrect BGP routes, essentially telling a huge portion of global internet traffic to go to the wrong address—or down a dead-end street. This misdirection overwhelmed healthy parts of Microsoft’s network and prevented traffic from being rerouted to backup systems.
The result? The authentication servers that were already struggling from the bad patch were now completely unreachable for millions. It was the digital equivalent of a city’s power grid failing at the same time all the roads leading to the power plant were suddenly demolished.
The Ripple Effect: Measuring the Global Impact
The impact went far beyond delayed newsletters and personal emails. For a world running on Microsoft’s ecosystem, it was an economic and operational body blow.
Economic Standstill: The Cost of a Silent Day
Analysts estimate the Microsoft Outlook Outage 2025 cost the global economy over $5 billion in lost productivity. Sales deals were missed, supply chain orders were not processed, and financial transactions were halted. Small businesses and freelancers who relied exclusively on Outlook for client communication were completely paralyzed.
Operational Chaos: Beyond Lost Emails
- Healthcare: Hospitals struggled to coordinate patient care as appointment reminders and inter-departmental communications failed.
- Logistics: Shipping companies couldn’t process customs declarations, leaving cargo stranded at ports.
- Legal & Finance: Time-sensitive contract executions and financial reporting were thrown into disarray.
The Road to Recovery: How Microsoft Stopped the Bleeding
Microsoft’s engineers initiated a two-pronged counter-attack:
- Software Rollback: They immediately began rolling back the flawed software patch from their Azure infrastructure. This was a delicate, server-by-server process to avoid further instability.
- BGP Correction: Simultaneously, they worked with global ISP and telecom partners to identify and stop the incorrect BGP announcements, allowing internet traffic to flow to the correct servers once again.
This monumental effort showcased the complexity of modern cloud infrastructure and the critical importance of both internal software quality control and external network partnerships.
Lessons Learned: 3 Ways to Prepare for the Next Inevitable Outage
The Microsoft Outlook Outage 2025 was a wake-up call. Here’s how you can be more resilient.
- Diversify Your Communication Channels: Don’t rely on a single provider. Ensure your team has a clear secondary communication tool (like Slack, Signal, or even a simple phone tree) and a protocol for when to use it.
- Implement Critical Offline Backups: For mission-critical information, cloud-only is a risk. Use solutions that allow you to maintain local or offline copies of essential contacts, documents, and calendars.
- Understand Your Provider’s Status Page: Know where to find and how to interpret your service provider’s status page. Microsoft’s Service Health status page became the world’s most-watched website during the crisis. Bookmarking it is essential.

Frequently Asked Questions (FAQs) – Microsoft Outlook Outage 2025
The outage was caused by a faulty software patch combined with a large BGP route leak from a third-party telecom provider. This made Outlook and other Microsoft 365 services unreachable for millions globally.
No. Microsoft confirmed that data was not lost—only access was affected. Once systems were restored, all emails, calendar events, and files remained intact.
Yes. While Microsoft has taken steps to improve resilience, complete uptime cannot be guaranteed. A strong business continuity plan is essential to reduce operational risks from future outages.
Use multiple communication channels (email, Slack, etc.), maintain offline backups, and create an internal outage response protocol. This layered approach will help your business stay connected and productive during disruptions.
Microsoft issued SLA-based service credits to eligible customers. However, these credits were minimal compared to the real-world costs of lost productivity and downtime, prompting many to reassess their resilience planning.
The Microsoft Outlook Outage 2025 will be remembered not just for the chaos it caused, but for the stark lesson it taught: convenience comes at the cost of dependency. While we rely on giants like Microsoft to keep our digital world running, ultimate responsibility for our own resilience lies with us. This event wasn’t the end of email, but it was the end of a certain kind of digital innocence.
By understanding what happened and taking proactive steps to diversify our tools and create contingency plans, we can turn this massive failure into a catalyst for a smarter, more robust, and more resilient digital future for everyone.
What was your biggest challenge during the outage? Share your experience in the comments below and let’s discuss how we can all be better prepared!
About the Author: AJH World
“AJH World” is a lead tech analyst and business continuity strategist with over 15 years of experience dissecting major IT infrastructure events. He helps businesses navigate the complexities of the digital landscape and build resilient operational frameworks.
Leave a Comment